Dilemme de base
J’ai cherché à savoir ce qui était le plus performant pour traiter une boucle en PHP. En posant la question à plusieurs développeurs, il n’y avait pas vraiment de consensus sur la méthode à utiliser. A vrai dire, la question sur la vitesse de lecture et d’écriture fait débat. Personnellement, je considère la lecture comme étant toujours plus rapide au niveau des disques durs en général c’est la vitesse de celle-ci qui est la plus élevée.
Voici deux exemples qui illustrent le dilemme. J’ai un tableau où j’ai envie de passer la valeur d’une sous-clé à la valeur true. J’ai cherché à savoir ce qui techniquement était le plus rapide entre écraser systématiquement la valeur ou alors faire un test pour savoir si c’est déjà la bonne valeur.
foreach($arr as $key => $value){
if( $value["sub_key"] != true ){
$arr[ $key ]["sub_key"] = true;
}
}
foreach($arr as $key => $value){
$arr[ $key ]["sub_key"] = true;
}
Et quoi de mieux que de faire les tests moi-même sur un tableau d’un million d’éléments.
Jeu de données
Voici la méthode qui génère le jeu de données. Je génère « is_valid » qui contient soit « no » soit « yes » ainsi qu’une seconde clé « verified » qui, dans certains cas, contiendra « yes » si « is_valid » est à true.
J’ai choisi de générer un million d’entrées. Dans mon cas, si je traite ce volume de données rapidement, je considère que le script sera suffisamment performant pour en traiter 1000 entrées. Même si d’expérience je sais que certains algorithmes peuvent être plus performants en fonction de la quantité à traiter.
public function generate_payload(){
for($i = 0; $i < $this->nbr_element; $i++){
$is_valid = rand(0,1);
$this->data[ $i ] = array(
"is_valid" => $is_valid == 0 ? "no" : "yes",
"verified" => rand(0,1) == 0 ? 'unknown' : ( $is_valid == 1 ? true : 'unknown')
);
}
file_put_contents("./payload.json", json_encode($this->data));
}
Méthode de benchmark
Le jeu de donnés est généré une seule fois et exécuté avant le traitement. Le temps de génération et de chargement n’est donc pas pris en compte mais uniquement le traitement du tableau.
J’exécute 10 fois le script sans opcache ou quoi que ce soit de spécial et j’enlève le premier temps, ce qui permet de lisser le temps, le premier chargement étant toujours un peu plus long. Ensuite au niveau de l’affichage du résultat, je fais une moyenne et je prends trois chiffres après la virgule. Je run le script plusieurs fois pour savoir si le résultat est stable, et si c’est le cas, alors c’est la valeur que je renseignerais.
Le test est fait sur un M2 dans un conteneur Docker. Je le précise car je ferai sans doute un complément de test sur un serveur Debian.
for($i = 0; $i<10; $i++){
$this->time_start = microtime(true);
$this->$function_name();
$this->time_end = microtime(true);
if( $i > 0){
$this->times[] = $this->time_end - $this->time_start;
}
}
Objectif
Au niveau du traitement c’est vraiment très simple. Je parcours l’ensemble des éléments du tableau et si « is_valid » est à la valeur « yes » alors je dois définir la valeur de « verified » à true.
L’objectif sera de faire des mesures et de comparer d’un script à l’autre quel est le plus performant en terme de temps de traitement.
Version 1 - Basique
Je pense qu’on pourra se mettre d’accord sur la base suivante qui fait exactement le travail. Il n’y a aucune particularité, c’est ce que pourrait coder un débutant et ce sera mon point de départ.
foreach($this->data as $k => $v ){
if( $v["is_valid"] == "yes" ){
$this->data[ $k ]["verified"] = true;
}
}
Le temps moyen de traitement tourne autour de 0,318 seconde. Sur 10 millions d’entrées, il y a eu 4995520 écritures, ce qui est cohérent avec le rand(0,1) (soit 50%).
Version 2 - lecture VS écriture
Dans ce second exemple, j’évite d’écrire la valeur true à chaque fois. Je fais un test afin de vérifier si la valeur est à « unknown » avant de la remplacer.
foreach($this->data as $k => $v ){
if( $v["is_valid"] == "yes" && $v["verified"] == 'unknown' ){
$this->data[ $k ]["verified"] = true;
}
}
De cette manière, je rajoute une condition et je fais beaucoup plus de lectures (> 500K) ce qui me fait perdre du temps. La moyenne est de 0,322 seconde ce qui est légèrement plus lent, malgré que l’on évite la ré-écriture dans certains cas.
Version 3 - &
Dans ce troisième exemple, j’utilise le symbole & qui permet de faire passer par référence la valeur à chaque itération. $v contient donc un pointeur et il n’y a pas de copie de variable à chaque fois.
foreach( $this->data as &$v ){
if( $v["is_valid"] == "yes" ){
$v[ "verified" ] = true;
}
}
On est sur 0,287 seconde, c’est plus rapide que la première solution.
Version 4 - Lecture + &
J’ai envie de voir ce que donne la lecture avec l’esperluette.
foreach( $this->data as &$v ){
if( $v["is_valid"] == "vino" && $v[ "verified" ] == 'unknown' ){
$v[ "verified" ] = true;
}
}
Avec un résultat de 0,295 seconde, ce n’est clairement pas le meilleur algorithme et ça reconfirme ce que j’ai mesuré au début.
Version 5 - array_keys
Dans cette version, je fais un array_keys qui me permet d’obtenir les clés du tableau. Je boucle sur ce tableau de clés et je référence aux variables grâce à celles-ci ainsi qu’au tableau $data.
foreach( array_keys($this->data) as $k ){
if( $this->data[ $k ]["is_valid"] == "yes" ){
$this->data[ $k ][ "verified" ] = true;
}
}
Le temps d’exécution est beaucoup plus rapide, je mesure 0,0615 seconde. C’est cinq fois plus rapide que la première version.
Version 6 - array_keys + & + lecture
Je tente l’utilisation de & qui me semble toujours plus performante ainsi qu’un test en lecture, même si deux exemples m’ont prouvé que la lecture est une mauvaise idée.
foreach( array_keys($this->data) as &$k ){
if( $this->data[ $k ]["is_valid"] == "yes" && $this->data[ $k ]["verified"] == "unknown" ){
$this->data[ $k ][ "verified" ] = true;
}
}
Lorsque je lance le benchmark, je mesure 0,088 seconde. C’est étonnamment beaucoup plus lent que la version 5. Je m’attendais à un écart mais pas aussi important.
Version 7 - for
Puisque dans les dernières versions j’ai utilisé array_keys, je pourrais enlever foreach au profit d’un for, puisque les clés de mon tableau sont des entiers qui se suivent.
$count = count($this->data) - 1;
for( $k = 0; $k < $count; $k++ ){
if( $this->data[ $k ][ 'is_valid' ] == 'yes' ){
$this->data[ $k ][ 'verified' ] = true;
}
}
Les performance explosent, je mesure une moyenne de 0,050 seconde. 1,23 fois plus rapide que la version la plus rapide mesurée jusqu’ici. Il faut savoir que plus je vais réduire le temps de traitement et plus ça va devenir difficile d’en gagner.
Version 8 - "y" VS "yes"
Ensuite j’ai tenté de tricher en effectuant seulement une partie de la comparaison. Comme la première lettre de « yes » est y et que « no » commence par « n », on peut simplement tester la première clé. Je me dis que c’est pas si bête, car on teste deux octets en moins.
$count = count($this->data) - 1;
for( $k = 0; $k < $count; $k++ ){
if( $this->data[ $k ][ 'is_valid' ][0] == 'y' ){
$this->data[ $k ][ 'verified' ] = true;
}
}
J’ai perdu en performance, 0,056 seconde c’est moins bon qu’avant. Je pense qu’en procédant de cette manière je force PHP à découper la chaine afin de tester une sous-partie, ce qui est beaucoup plus lourd.
Version 9 - inverser les conditions
Si « verified » est déjà à la valeur true, on sait qu’on n’a pas besoin d’écrire car la valeur est déjà bonne. On peut donc positionner le test avant le « is_valid ». En plus de cela, je vais aussi utiliser l’opérateur !== qui va tester le type de la variable, ça évitera à PHP de transtypage qui prend plus de temps (enfin je pense).
En PHP ‘unknown’ == true est évalué à true tandis que ‘unknown’ === true est évalué à false.
$count = count($this->data) - 1;
for( $k = 0; $k < $count; $k++ ){
if( $this->data[ $k ][ 'verified' ] !== true && $this->data[ $k ][ 'is_valid' ] == 'yes' ){
$this->data[ $k ][ 'verified' ] = true;
}
}
Ça donne un temps d’execution de 0,044 seconde, soit le temps le plus rapide mesuré jusqu’à présent.
Version 10 - array_map
J’ai pu lire sur différents blogs qu’utiliser un array_map pouvait améliorer les performances. Dans mon cas, j’ai testé trois méthodes différentes. Faire appel à une méthode, injecter en closure ou faire appel à une fonction en dehors de la classe. J’ai chaque fois eu de mauvais résultats.
array_map(function($item){
if( $item[ 'verified' ] !== true && $item[ 'is_valid' ] == 'yes' ){
$item[ 'verified' ] = true;
}
}, $this->data);
Un temps de 0,317 seconde, soit la même chose que l’exemple 1.
Version 11 - if imbriqué
Par curiosité, je me suis demandé si ce n’était pas plus efficace d’imbriquer les if. Dans l’expression, il doit au moins atteindre && et faire une sorte de calcul supplémentaire pour savoir s’il doit évaluer ou non le reste de l’expression, si c’est imbriqué il ne le doit pas.
$count = count($this->data) - 1;
for( $k = 0; $k < $count; $k++ ){
if( $this->data[ $k ][ 'verified' ] !== true ){
if( $this->data[ $k ][ 'is_valid' ] == 'yes' ){
$this->data[ $k ][ 'verified' ] = true;
}
}
}
Alors c’est vraiment du détail, mais après avoir fait plusieurs mesures sur 100 millions d’éléments, on gagne un tout petit peu et ça ramène le temps d’exécution à 0,043 secondes. Je ne sas pas si c’est dû à cela mais j’ai préféré le noter car le résultat me semble faire du sens.
Comparaison
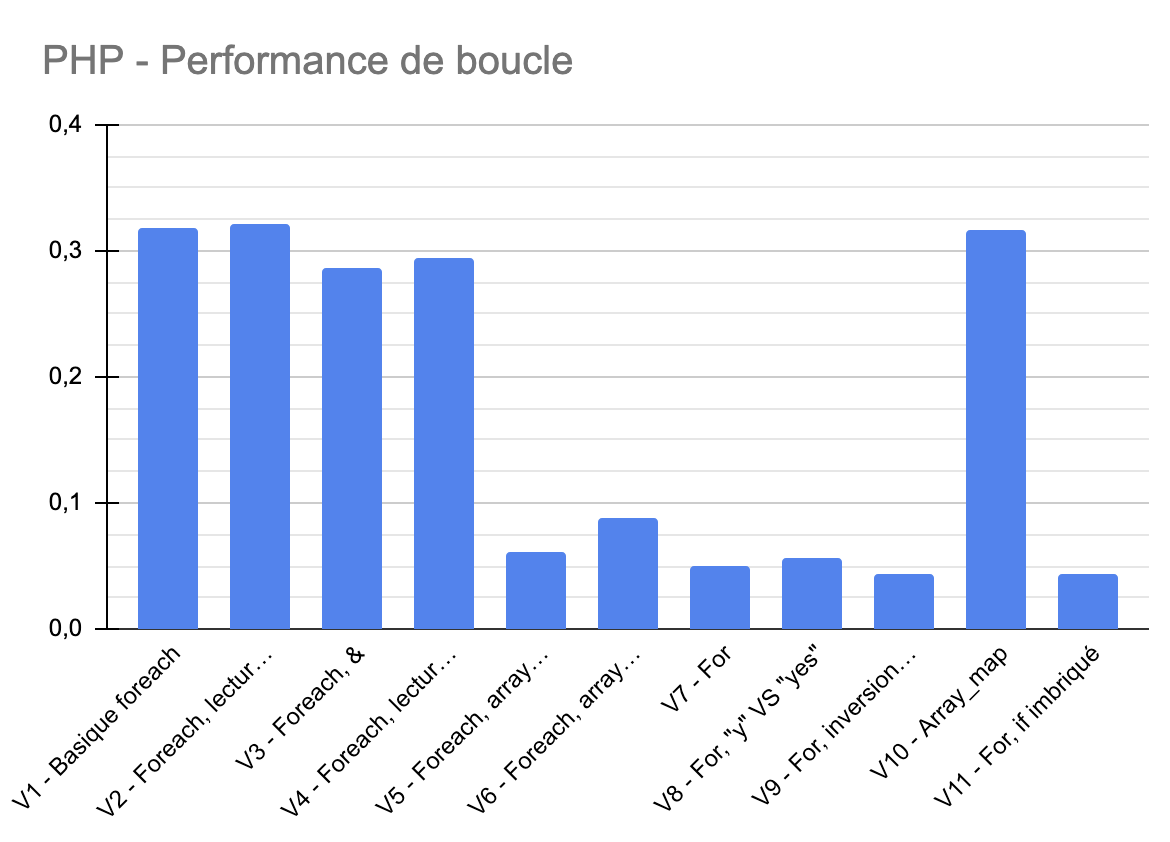
Voici graphiquement la comparaison. Plus c’est petit et plus c’est performant. Tu peux voir que d’une technique à une autre on peut avoir des écarts assez importants. Cela veut dire que si la problématique est de traiter des volumes considérables de données, la technique d’écriture sera tout aussi importante que le choix de l’algorithme.
La version 9 est la plus performante.
Analyse
En ayant fait ces tests, je me rends compte que c’est le nombre d’opérations qui compte. Dès qu’il y a significativement plus d’opérations, le temps de traitement sera plus important. Effectuer des lectures supplémentaires allonge le temps de traitement.
Utiliser des pointeurs via & est plus intéressant, on ne re-stock pas la donnée dans une nouvelle variable mais simplement la référence de celle-ci. Je pense que cela a encore plus d’intérêt avec de grosses variables.
Manipuler des booléens est très intéressant, on peut faire des tests en évitant au langage de transtyper ce qui est coûteux en temps.
Si c’est un tableau parfaitement ordonné en terme de clés, c’est-à-dire 0, 1, 2, 3… Il n’à a pas de logique à itérer sur un tableau et encore moins à utiliser un foreach. Faire le choix d’une boucle for sera beaucoup plus performant.
C’est hypothétique de ma part, mais imbriquer des if pourrait faire gagner au moins un calcul. Même si c’est compilé à chaque itération, le programme doit évaluer en plus un && ou un || si les conditions sont sur la même ligne. Avec la technique que j’ai utilisée, dans 50% des cas il n’en a pas besoin.
Conclusion
En prenant un algorithme de base et celui pour lequel j’ai réussi à faire la plus grande optimisation, j’arrive à un gain de temps d’un facteur 7.
Pour la conception d’un site web, je considère ce gain de temps comme marginal et négligeable. J’ai utilisé un échantillon de données très élevé par rapport aux quantités que je manipule habituellement. Dans cette situation, je pense qu’il sera préférable de garder un code plus lisible que de chercher à obtenir de la performance.
En générale un développeur sera confronté à d’autres problèmes de performance avant de devoir optimiser des écritures de boucle. Optimiser des requêtes SQL, mettre en place du cache, bien d’autres améliorations avant d’en arriver jusque là.
Ce que j’en retire aussi, c’est qu’il ne faut pas faire confiance à ce qu’on peut trouver sur internet et encore moins aux intelligences artificielles (pour le moment). La plupart des blogs recommanderont l’usage du foreach alors que ce n’est pas le plus performant. D’autre des fonctions natives telles que array_map alors que ce n’est clairement pas le plus efficient non plus. Des développeurs ne vous recommanderont pas d’avoir des niveaux d’imbrication trop profonds, là encore ce sera discutable et ce choix sera plus une question de lisibilité de code que de performance.
Si un jour tu te confrontes à ce genre de question ou que tu es à la recherche de performance, fais les tests et les mesures toi-même avec ton propre contexte. Tu en ressortiras avec plus de connaissances et une application qui sera plus rapide, en tout cas tu en auras plus de certitude que de conviction.
15/09/2024
Yann Vangampelaere - nouslesdevs -