Prologue
Ça y est, c’est parti pour la grande aventure Træfik ! Je pense que je n’ai pas eu autant d’excitation depuis le jour où j’ai entamé la série sur le jeu vidéo. Depuis le temps, il s’en est passé des choses !
Initialement, j’ai creusé le sujet du reverse proxy pour résoudre un problème très simple qui consistait à restreindre l’accès à des environnements de staging uniquement à notre IP, afin d’éviter que les moteurs de recherche ne puissent indexer un site de test. J’en ai d’ailleurs fait un mini-article, si la démarche initiale t’intéresse.
Maintenant, il est temps de rentrer dans le vif du sujet et de t’expliquer à quoi sert un reverse proxy, comment on le met en place, ce qu’on peut attendre d’un outil comme celui-ci et jusqu’où on peut aller avec. Bref. Une série d’articles qui s’annonce passionnante et qui, je l’espère, te fera adopter l’outil !
Connaissances requises
Pour utiliser Træfik et comprendre ce que l’on fait avec, l’idéal est d’avoir une vue d’ensemble de l’architecture d’un projet web et de comprendre le fonctionnement basique d’une requête HTTP. Avoir quelques acquis en Linux et avoir configuré au moins une fois dans sa vie une zone DNS me semble être le minimum. Disons que ce sont quelques prérequis pour être à l’aise avec les articles qui vont suivre. J’essaierai, pour ma part, d’être le plus pédagogue et le plus simple possible.
Reverse Proxy
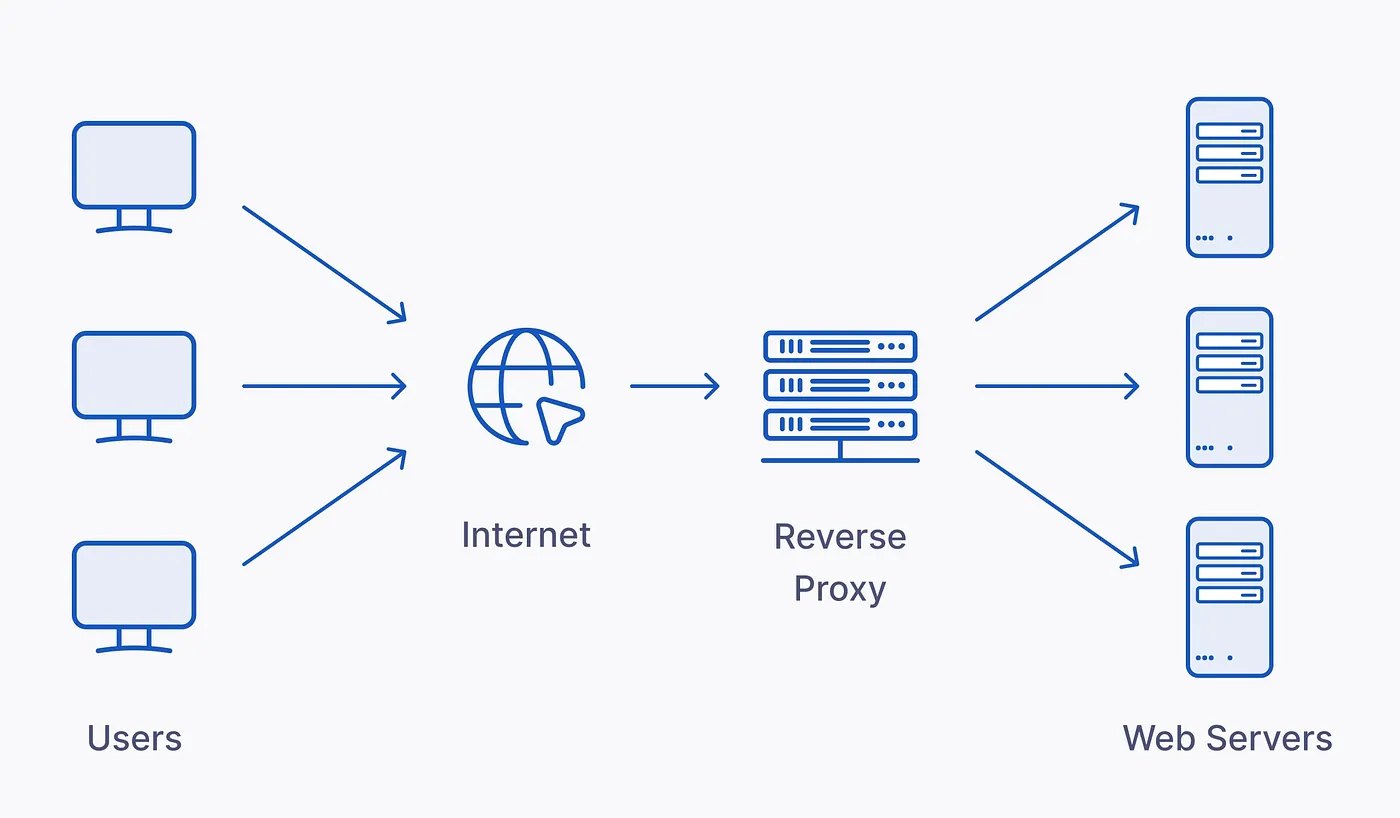
Un reverse proxy est un logiciel qui s’installe sur un serveur et qui joue le rôle d’intermédiaire entre des clients qui souhaitent accéder à une page web et un serveur qui héberge ton site internet.
On lui envoie toutes les requêtes et, en fonction de sa configuration, il va pouvoir dispatcher ces requêtes vers le serveur qui se trouve derrière, récupérer la réponse et la renvoyer au client.
Pourquoi un reverse proxy
Pour comprendre à quoi peut bien servir un reverse proxy, on va regarder cela sous le prisme de la cybersécurité.
Quand un site web est en ligne, on cherche à garantir deux choses, sa disponibilité et son intégrité. Ces deux objectifs sont extrêmement compliqués à atteindre lorsqu’on est exposé sur Internet.
L'intégrité
La première chose à comprendre, c’est que le serveur final (la machine tout à droite dans le schéma) n’est pas connu du public, c’est-à-dire que les gens ne connaissent pas son adresse IP. Limiter son exposition et sa visibilité réduit de surcroît sa surface d’attaque, et c’est l’un des points essentiels à comprendre, car le reverse proxy joue un rôle très important en matière de sécurité. Moins d’attaques signifie plus de chances de préserver l’intégrité.
Imagine-toi comme si tu étais une célébrité et que le reverse proxy était ton garde du corps. Chaque fois qu’on veut te parler, cela doit passer par lui. Il t’apporte les messages, tu y réponds, mais personne ne peut réellement entrer en contact avec toi. C’est exactement la même chose pour ton serveur.
Je tiens à préciser ici que ce n’est pas parce que tu as un reverse proxy que tu es protégé de tout, bien au contraire. Tu dois toujours veiller à construire des sites web sécurisés.
La disponibilité
Le second point, c’est la charge, c’est-à-dire le fait que le serveur reçoive énormément de visites. Un reverse proxy est capable d’absorber une grande quantité de requêtes et soit de les dispatcher vers plusieurs serveurs situés derrière, ce que l’on appelle un load balancer, soit de les bloquer si cela risque de mettre en péril leur capacité de réponse. D’ailleurs, lorsque cela se produit on parle généralement de flood ou de DDoS.
Tout va s’articuler autour de ces deux composantes, sa capacité de blocage ainsi que sa capacité de routage.
Enfin, ce n’est pas parce que tu as un reverse proxy que cela t’exonère d’optimiser un minimum les choses et d’améliorer le temps de réponse de tes pages web.
Centralisation
L’un des avantages sous-jacents, c’est la centralisation de la sécurité. Comme un reverse proxy est capable d’absorber une grosse quantité de requêtes, à mon échelle, je peux mutualiser et faire passer les requêtes de plusieurs sites web à travers un seul reverse proxy. De cette façon, je renforce un point de passage unique afin d’améliorer la sécurité de plusieurs domaines à la fois.
Træfik
Cela m’amène donc à Træfik, qui est un reverse proxy se voulant simple d’utilisation et moderne. C’est un outil qui a été développé en Go, qui est open source et dont Emile Vauge est l’instigateur.
Je ne pense pas être très objectif, ayant à peine effleuré d’autres technos comme Nginx ou HAProxy, mais je trouve Træfik incroyable. Tout réside dans sa simplicité et dans sa compréhension. La mise en place est extrêmement rapide, il faut seulement quelques minutes pour faire fonctionner un Træfik. L’utiliser, c’est s’exposer à s’exclamer au bureau un bon « putain, ça marche bien ».
Architecture et Træfik
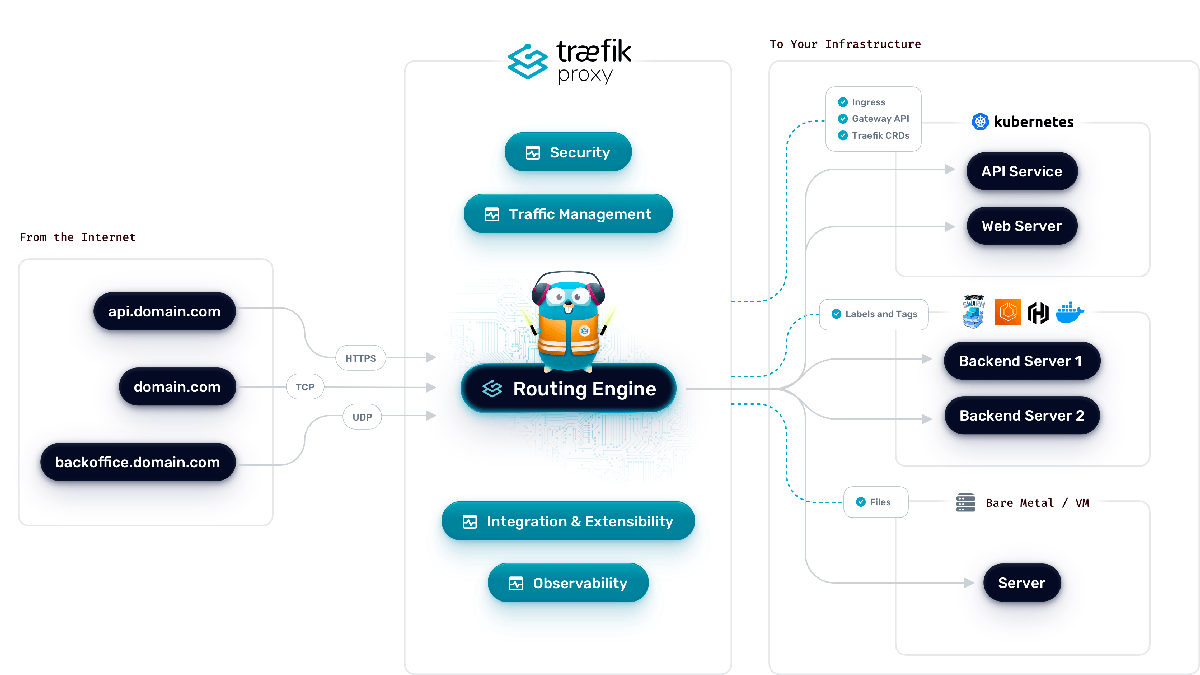
Dans le schéma ci-dessous, un peu plus détaillé, tu peux voir où s’intercale Træfik.
À gauche, on se place du côté d’un visiteur qui va demander une page web au travers de son navigateur, par exemple via une requête HTTPS. Au milieu, nous avons le reverse proxy, Træfik, qui va détecter l’appel et opérer le routage via une configuration qu’on lui aura fournie. Ensuite, sur le côté droit, se trouvent l’ensemble de nos serveurs ou services qui vont recevoir les appels.
Brancher Træfik
Habituellement, lorsqu’on achète un nom de domaine, on pointe le champ A vers l’adresse IP du serveur web. Lorsque j’évoque le fait d’envoyer toutes les requêtes à Træfik, ce que je veux dire, c’est que l’on va faire pointer notre domaine vers l’IP du reverse proxy à la place de celle du serveur web, afin de lui envoyer tout le trafic.
Concepts clés
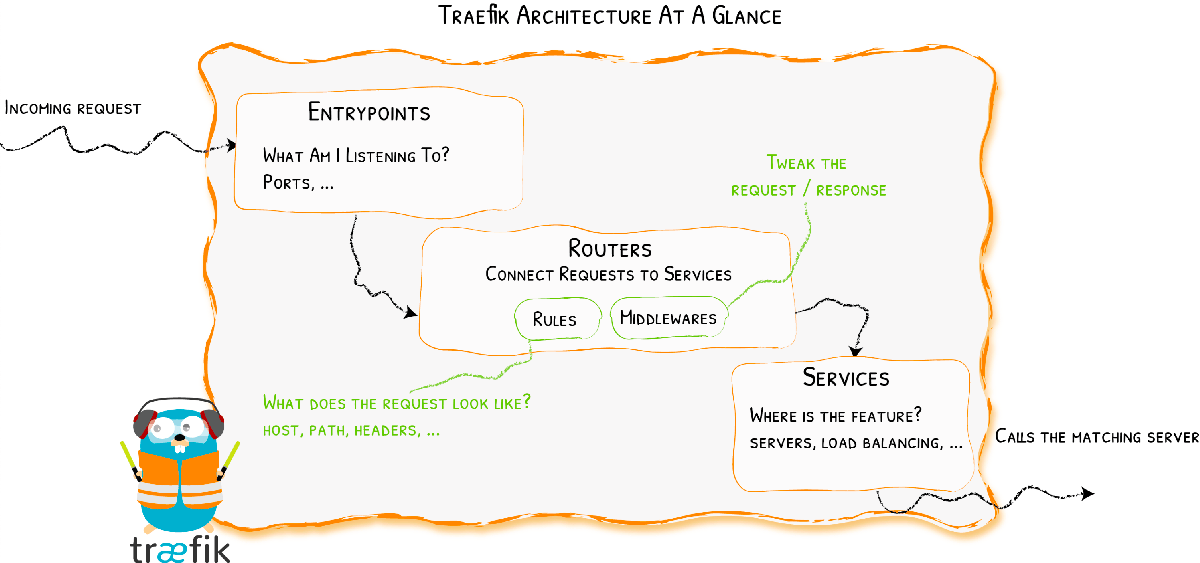
Træfik repose sur quatre briques, les points d’entrée, les routeurs, les middlewares et les services.
Le schéma ci-dessous permet déjà d’avoir une bonne idée de comment ça marche, mais je vais m’autoriser une petite explication.
Dans la mise en place de Træfik, la première chose à faire est de définir des points d’entrée, c’est-à-dire les ports que le reverse proxy pourra écouter. En tant que développeur web, on aura au minimum le port 80 (HTTP) ainsi que le port 443 (HTTPS).
Les routeurs sont un branchement, une partie de la configuration qui fait la liaison entre une requête et un service. Un routeur est composé d’un entrypoint, d’une règle et d’un service. L’entrypoint indique typiquement sur quel port le routeur s’applique. La règle correspond à une condition qui va déterminer si le routeur doit s’appliquer. Par exemple, une règle pourrait être de détecter si le domaine est nouslesdevs.com, tout simplement. Enfin, le service précise sur quel service envoyer le trafic.
Les middlewares sont une partie importante de Træfik et permettent d’effectuer certaines actions, soit avant d’envoyer une requête, soit après. Les middlewares ont le pouvoir de bloquer des requêtes, par exemple, ou bien de réécrire le chemin de l’URL.
En dernier lieu, il y a les services, qui peuvent être une simple adresse IP, une URL ou encore un ensemble de plusieurs serveurs, lorsqu’il y a une configuration de load balancer, par exemple. C’est vers l’un d’entre eux qu’un routeur enverra la requête.
De quoi a-t-on besoin ?
Pour pouvoir utiliser Træfik, il faut simplement un serveur Linux et un peu de matière grise !
Moi, ce que je préconise, c’est de faire tes premières expérimentations sur un EC2 d’Amazon. Selon moi, c’est le plus simple et le plus efficace pour démarrer avec Træfik. Si jamais tu es à l’aise avec Docker, ça peut être intéressant d’apprendre en local, mais tu vas te rajouter une complexité supplémentaire. Moi, je le verrais plutôt dans un second temps.
La courbe d’apprentissage
Au niveau de la courbe d’apprentissage, tu n’as pas d’inquiétude à avoir. Une fois les premiers routeurs posés, le reste vient vraiment tout seul ! Lorsque tu franchis une étape ou que tu réussis à réaliser une configuration particulière, tu pourras facilement la réexploiter et repartir de celle-ci.
L’un de mes objectifs pour cette série de tutos est de te former et de partager avec toi ce que j’ai appris sur Træfik via des exemples concrets issus des besoins de mon travail. L’idée est de progressivement monter en complexité et de tendre vers quelque chose de linéaire et de digeste.
Prêt pour la découverte
Bon, je pense qu’il est temps de clôturer ce premier article sur le reverse proxy, qui plante un peu le décor.
Si tu es arrivé jusqu’ici, alors je suis sûr que je te reverrai très prochainement sur mon blog pour ce qui devrait être l’installation de Træfik.
01/01/2026
Yann Vangampelaere - nouslesdevs -